Zombie Dependencies
More haunted dependencies in the jungle
This is Part Two of my Dependency Jungle series. (Part 1 here). I’m trying to better understand how large networks of projects manage dependencies, vulnerabilities and upgrades, so I decided to spend some time doing it myself. By documenting and sharing this experience, I’m hoping we can come up with ideas to systematically improve this process, making it faster and easier for real-world projects to stay up to date and secure.
From time-to-time I live-tweet these adventures, so consider following me on Twitter for some bite-sized versions of archaeology like this.
In the last post of this series I talked about ghosts. Dependency ghosts are mostly harmless artifacts from another time, floating around in the dependency graph haunting anyone that dares to look. Ghosts don’t mess up your build process, and they usually can’t introduce a vulnerability on their own. They are relatively friendly. This post is about a different, scarier type of dependency — a Zombie. Zombies are mostly-dead packages. Maybe they’ve been formally deprecated, archived or even placed into “maintenance mode”. But they’re still there, happily running in your program, bugs and all.
You might ask, what’s the issue? Why fix what isn’t broken? The problem is that all software is broken — we just don’t always know how yet. Later, when you find the bugs, there might be no one around to fix them, or even to merge a fix you write. You might be stuck forking the code or hoping someone else steps up to do so. And even worse — if multiple people start maintaining forks of the same code, you can end up with a proliferation of slightly incompatible libraries leading straight to dependency hell.
A few zombies in your tree isn’t a big deal. Zombies don’t move particularly fast, but they do pile up if you’re not vigilant. One is nothing to be afraid of. Dozens of zombies though? Now you should be starting to get worried. And unfortunately, they tend to multiply over time.
Zombie dependencies are hard to spot, sometimes even indistinguishable from normal ones. How can you tell if a library is simply “complete” and doesn’t need many changes, or if it has been abandoned and a pile of unfixed CVEs is lurking inside?
While tracking down the rsc.io/sampler Ghost dependency in the first part of this series, I noticed a few zombies in the Kubernetes vendor tree. I decided to try removing these as well, once and for all. This post describes what that process looked like, and some useful tricks I discovered along the way.
CVE Scans
CVE scanning on open source packages is usually a needle in a haystack situation. These tools are notoriously noisy, they output anything that might even be a CVE. This makes sense — it’s better to be overly cautious here. Unfortunately that means it’s hard to see what actually needs your attention. Still, a noisy CVE scan is better than trying to make sense out of the full dependency graph. After fixing the rsc.io/sampler issue, I decided to fire up snyk test to see what it found in Kubernetes.
The output was about what I expected. Over 20 issues were reported, but most of them seemed like strange false positives. Most were actually vulnerabilities in older versions of Kubernetes itself, which had already been patched. Something weird must have been happening with the way modules get resolved. But, there were three CVEs that caught my attention at the bottom:
✗ High severity vulnerability found in github.com/satori/go.uuid
Description: Insecure Randomness
Info: https://snyk.io/vuln/SNYK-GOLANG-GITHUBCOMSATORIGOUUID-72488✗ High severity vulnerability found in github.com/miekg/dns
Description: Insecure Randomness
Info: https://snyk.io/vuln/SNYK-GOLANG-GITHUBCOMMIEKGDNS-537825✗ High severity vulnerability found in github.com/dgrijalva/jwt-go
Description: Access Restriction Bypass
Info: https://snyk.io/vuln/SNYK-GOLANG-GITHUBCOMDGRIJALVAJWTGO-596515
I started at the top, to see if I could fix any of these.
go.uuid
The class of vulnerability here is called “Insecure Randomess”. The issue/fixes discussed are a little hard to follow, but it appears the library was not properly generating random UUIDs. It doesn’t appear that a fix is available, and the repository has a handful of pending PRs and Issues asking about the state of this fix and the library as whole.
Another one reads “PSA: This repo is dead”.
I realized about now that I was definitely looking at a Zombie. This repo is clearly dead, but it’s also clearly still alive, hanging out in the vendor tree of some of the most critical Golang projects in the world.
How do you get rid of a Zombie? You can’t upgrade your way out — you have to replace it. Some searching led me to a fork created by a community group called the gofrs just for this purpose — to fork, fix up and maintain abandoned packages like this.
But then came the hard part: actually doing the swap. It’s relatively easy to force an update to a package, even a transitive one. It’s much harder to swap it out for an entirely different package, even one that’s a fork intended to be compatible with the original. We have to change everything else in our import tree to use this fork.
I went back to the toolbox to see where it was coming from how hard this was going to be:
$ go mod why github.com/satori/go.uuid
# github.com/satori/go.uuid
k8s.io/kubernetes/cmd/cloud-controller-manager
k8s.io/legacy-cloud-providers/azure
github.com/Azure/azure-sdk-for-go/storage
github.com/satori/go.uuidSo, this is coming from another k8s package that in turn imported some Azure dependencies. I started looking at the bottom, in the Azure packages. A quick glance at that repo showed a work in progress PR to do this very swap. Unfortunately, the PR was about a month old and it wasn’t clear what was holding it up.
This is bad for a few reasons: in addition to the amount of work required to do the swap, a non-trivial fix also indicates that the vulnerable code is actually in use and not just an unused ghost in the dependency graph.
The maintainers of the repo got back to me pretty quickly indicating that they were working on this one, although there was no specific timeline to getting it merged. I offered my help, then decided to move on and try my hand at another CVE in the list.
It’s Never DNS
The next one up was another insecure randomness issue, this time in a DNS library. The go mod why command indicated that this was a direct dependency:
$ go mod why github.com/miekg/dns
k8s.io/kubernetes/pkg/proxy/winuserspace
github.com/miekg/dnsA direct dependency is good and bad news — it’s more likely we’re affected by the CVE, but we also have complete control of the fix. This was already fixed upstream, and it turned out to be a pretty trivial dep update. The maintainers realized that this was actually a pretty small dependency, and instead opted to first try to remove it completely. Even better! Unfortunately that turned out to be harder than anticipated, and the always helpful dims pushed this one through!
JWT, My Old Friend
Last on the list was a package I’ve dealt with before: dgrijalva/jwt-go. I hunted down and applied some updates here for some of my other projects in an earlier blog post. This JWT library is another perfect example of a Zombie — an abandoned package that has made its way into the dependency trees of dozens and dozens of widely used Go repositories. I had some success getting rid of this in Tekton, so I decided to try my hand at it in Kubernetes. Some zombies are tougher than others, unfortunately.
At first glance, this one seemed simple. There’s a widely used, mostly maintained fork of this repo over at github.com/form3tech-oss/jwt-go. Many projects have already started to move over there. So, I started at the bottom to see if I could just update my way out of this one too. Starting with go mod why:
$ go mod why github.com/dgrijalva/jwt-go
# github.com/dgrijalva/jwt-go
k8s.io/kubernetes/pkg/volume/glusterfs
github.com/heketi/heketi/client/api/go-client
github.com/dgrijalva/jwt-goThis didn’t look too bad. Only one out-of-tree dependency in the way. I jumped over to that repo and did some digging. A few warning signs immediately flashed on my screen. This repo was still using glide, a tool several generations behind in the rapidly evolving Go dependency management world. Further, there was a pending PR to announce that the project was going into “hard maintenance” mode. I found a double-Zombie! A zombie dependency importing another zombie dependency. I was starting to feel surrounded.
I wasn’t ready to give up yet though. The description of maintenance mode here indicated that critical fixes could still go in, so I decided to give it a try. I spun up a docker image with an old version of Go to try to get glide working again, and got an update prepared in a pull request. No good deed goes unrewarded, and I was immediately hit with some failing tests. After some trial-and-error/debugging, I had a PR sent up. Of course, things are never that easy.
The CI system failed with a timeout, then with an unrelated vagrant/Ruby issue. Hopefully the Jenkins gods and maintainers eventually take pity on me.
I was still waiting on the PR to be merged, but I also didn’t really have any evidence this is all I would need to do the full swap. The go mod why tool only displays one of the possible reasons a library is being imported — it’s basically a BFS of the dependency tree that exists when it finds the first import. While I was waiting, I decided to keep looking through the graph and find out if there was anything else that needed to be updated. A couple others appeared in this search:
github.com/auth0/go-jwt-middleware
github.com/spf13/viper
go.etcd.io/etcdI started at the top here. go-jwt-middleware had a PR pending for several months to do this swap. I gave my +1 of support, then checked back in a few weeks later with the maintainer on Twitter after a few more weeks. He replied immediately and they got a plan together to update! Open Source can be amazing.
Next up the stack was viper. I’ve used viper before and am pretty familiar with it, so I cloned the repo and made my changes. It was a pretty easy update, so I sent a PR. Right after hitting submit, I realized there were already a few pending. The maintainers explained that they can’t do this update until etcd cuts another release due to some issues with go modules.
I hopped over to etcd, saving the biggest for last. Updating etcd in k8s did not strike me as an easy task. The current version in the import graph was 0.5.0-alpha, which never actually got turned into a real release. The latest in the etcd tree is a new major version, called 3.5. These are treated as fundamentally different modules by Go. I decided to see if doing that update would even fix things, so I cloned the repo and checked why etcd was using jwt:
$ go mod graph | grep jwt
github.com/spf13/viper@v1.7.0 github.com/dgrijalva/jwt-go@v3.2.0+incompatible
go.etcd.io/etcd/server/v3@v3.5.0-pre github.com/dgrijalva/jwt-go@v3.2.0+incompatibleWat?
What? etcd imports viper, which imports etcd, which imports jwt-go? If you thought circular dependencies were impossible in Go, you’re only mostly correct. Dependency graphs between modules form a DAG (directed acyclic graph), but then how can we have a cycle like this? The answer is that the DAG only applies to specific module versions. Cycles can exist if you ignore versions. The picture below explain this a bit better than I can with words:
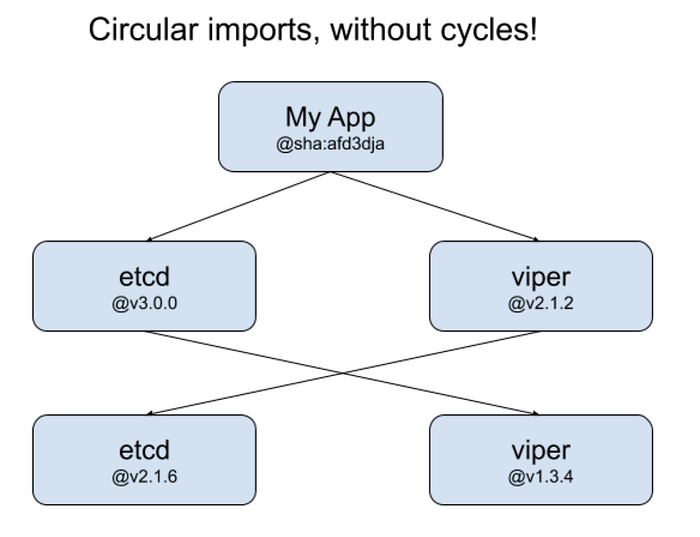
Now What?
We have a Zombie train! The viper library can’t update until etcd does, but etcd uses viper! So I think to get this fixed everywhere, etcd and viper need to first do a release with the direct dependencies swapped out, Then they both need to update each other. But this is pretty confusing, and there could easily be even more places pulling in this dependency (directly or not).
I wanted to sanity check this, so I did kept looking in the etcd tree itself. At this point I was thoroughly confused, but etcd also uses the vulnerabledgrijalva/jwt-go library directly, all over the place! Including in a package called “server/auth”.
I searched the issues and PRs and didn’t see anyone currently working on this. Somehow I was the first one to notice etcd was using a vulnerable auth library, for auth? Assuming the “many eyes” problem will always fix your issues for you is clearly not a good idea.
I don’t really know a ton about JWT, but it looked like this particular CVE had to do with validation on the aud field. I didn’t see any usage of that field in etcd, but it seemed like a god idea to switch anyway just in case someone uses that field later or another issue comes up. (Also, I still couldn’t tell if this swap would be needed to fix the circular dependency issue with viper, but that can come later I guess).
It took me a while to figure out how etcd handles the multi-module setup they have in their “mono-repo”, but I eventually got tests passing and fired off a PR there. This one also took a couple cycles of debugging failing/flaky tests, but eventually I got all green status checks. Still waiting on a maintainer review here.
Wrapping Up
I want to finish by reiterating that projects get abandoned over time, and it’s no one’s fault. People get new jobs, their life circumstances change, whatever. I’m sure everyone reading this is guilty of starting on a small side project and getting bored or moving on. The magic of open source is that these small side projects can be reused and combined into something bigger! The horror is that sometimes the creators of these small side projects had no idea someone was building a critical application on top of their code. It is the responsibility of those using OSS to make sure it works, and that they have a contingency plan to make changes if they need to. This comment from the Apple Objective C compiler best summarizes how you should treat any dependency you take on:
* These will change in arbitrary OS updates and in unpredictable ways.
*When your program breaks, you get to keep both pieces.
So, what did I accomplish here? In total, I sent about 6 PRs to a bunch of different repositories that somehow sit both upstream and downstream of Kubernetes. I only managed to fix one reported CVE (the DNS one), and it wasn’t clear whether or not this was actually in use.
I did manage to move a bunch of other projects one PR closer to being able to move off of some Zombie dependencies, though. Some of these were even double zombies, or circular rings of zombies. I’ll keep following up on these fixes and trying to get them all the way upstream over time. Zombie hunting is a tedious task with no immediate reward. I like to think that I saved some future person a few PRs and weeks of waiting for merges here.
I had the benefit of not being in any kind of time pressure, even though I was working to eliminate flagged CVEs. Imagine having to do something like this for an actively exploited security vulnerability! In order to fix a security issue in your software, you’re relying on maintainers you don’t know who may or may not even be checking email. Reusing code is great, but it’s important to have a plan for what to do if you can’t get a fix in that you need.
I hope I didn’t annoy too many maintainers throughout this process, and a big thank you to everyone for patiently answering my questions and helping me get my PRs merged! Coming up next will be a post on the newest cloud native configuration format: PDFs!
